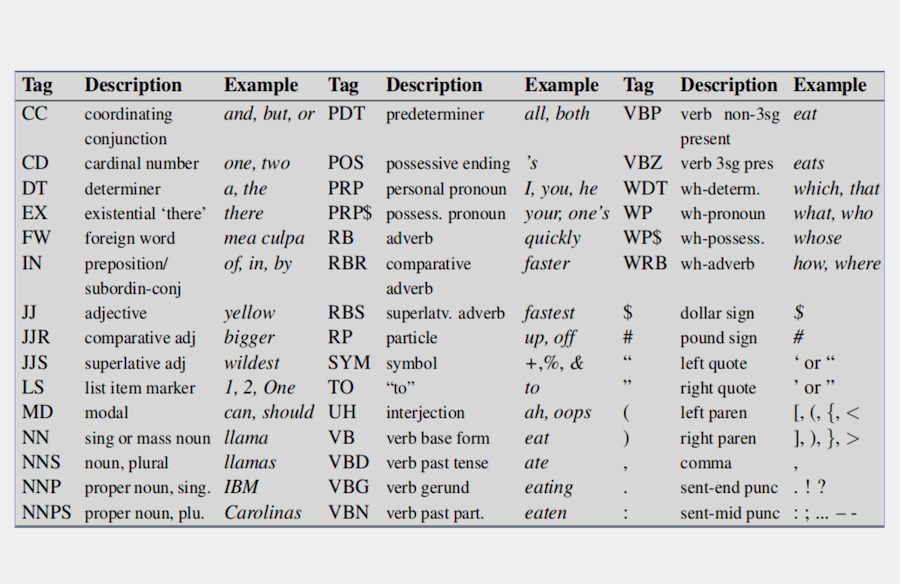
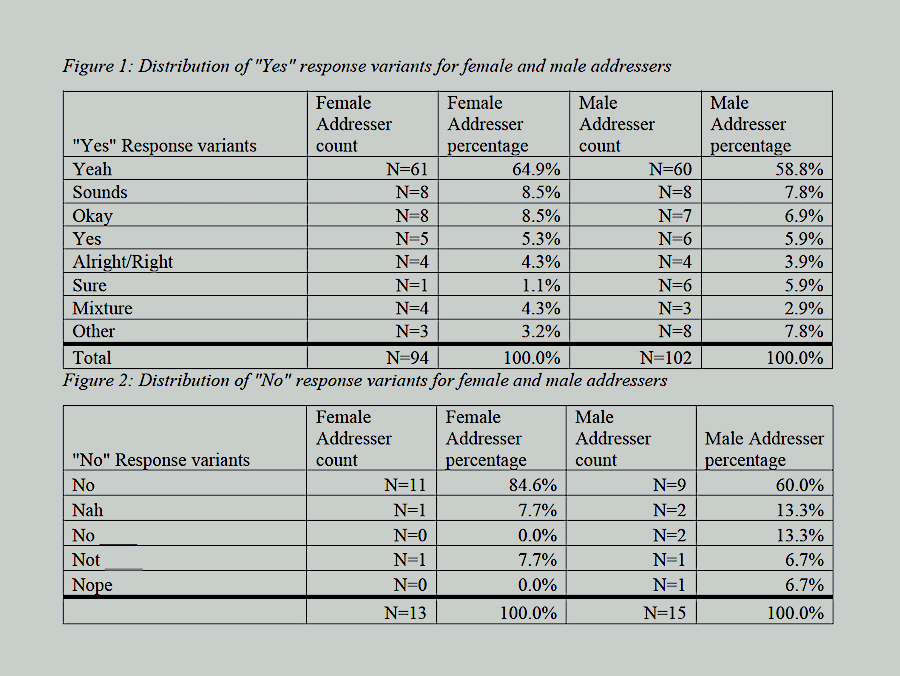
Machine Learning Mapping NO2 datasets
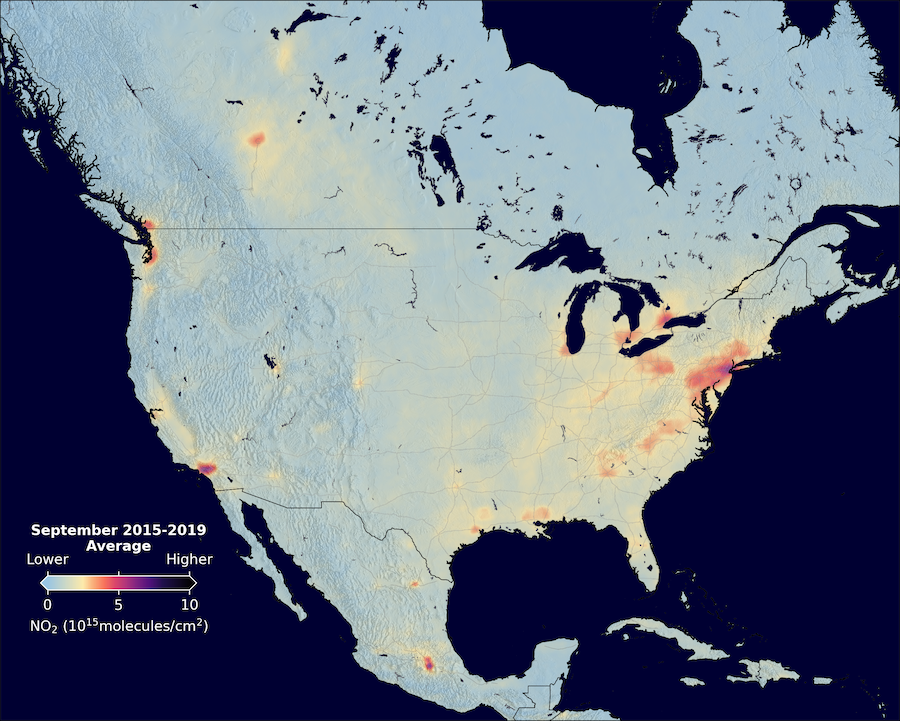
Tracking global NO₂ levels over time is crucial for monitoring climate change. To address this, the Cohen Research Group developed the Berkeley High-Resolution NO₂ Product (BEHR) using the WRF-CHEM climate model to generate high-resolution NO₂ measurements, accounting for spatial and seasonal variations in data recorded by NASA’s Aura satellite. Building on this work, I laid the groundwork for a Machine Learning model designed to replace the computationally intensive WRF-CHEM model. I aligned over 47K WRF-CHEM pixels with OMI pixels, improving data correlation for ML model training, and engineered the geolocation data to streamline analysis and enhance interpretability.